window size 조절
browser = await launch(headless=False,
ignoreHTTPSErrors=True,
ignoreDefaultArgs=['--enable-automation'],
args=['--window-size=800,600'])
js 사용하기
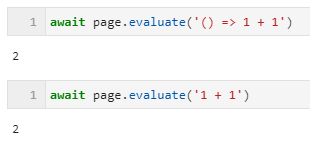
await page.evaluate('(el) => el.value = ""', elem)
await page.evaluate('(el) => el.click()', btn[0])
.getProperty로 안될 때 evaluate 이용해서 .getAttribute 사용
li_elements = await page.querySelectorAll('.thmb')
for ind, li in enumerate(li_elements):
a = await page.evaluate("(element) => element.getAttribute('data-a')", li)
img_element = await page.evaluate('document.querySelector("img")', force_expr=True)
XPath 문법
형제 div 선택 : following-sibling::dv
await page.xpath(f'//*[@id="{id}"]/following-sibling::div')
waitForXPath
옵션
- visible (bool): wait for element to be present in DOM and to be visible, i.e. to not have display: none or visibility: hidden CSS properties. Defaults to False.
- hidden (bool): wait for element to not be found in the DOM or to be hidden, i.e. have display: none or visibility: hidden CSS properties. Defaults to False.
- timeout (int|float): maximum time to wait for in milliseconds. Defaults to 30000 (30 seconds). Pass 0 to disable timeout.
btn-login 기다렸다가 클릭
await page.waitForXPath('//button[@class="btn btn-login"]', { 'visible': 'true', 'timeout': 100000 })
btn_login = await page.xpath('//button[@class="btn btn-login"]')
await btn_login[0].click()
https://www.tools4testing.com/contents/puppeteer/puppeteer-waitforxpath
Puppeteer waitForXPath - tools4testing
page.waitForXPath method is used to wait for the element/elements represented by the xpath to appear or to disappear from the page. waitForXPath method returns the promise with the element handle which is represented by the selector expression and null if
www.tools4testing.com
https://miyakogi.github.io/pyppeteer/reference.html#pyppeteer.page.Page.waitForXPath
API Reference — Pyppeteer 0.0.25 documentation
Return awaitable object which resolves to a JSHandle of the success value.
miyakogi.github.io
오류 발생
pyppeteer.errors.PageError: net::ERR_SSL_VERSION_INTERFERENCE at https://google.com
chromium 열어서 들어가도 접속이 안됨
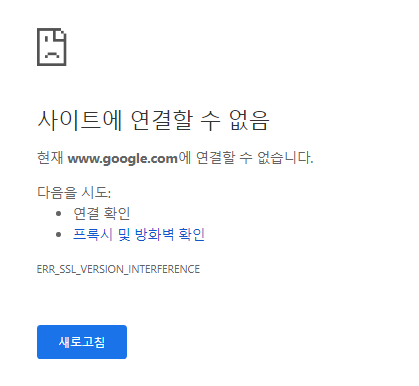
chrome://flags/ 들어가서 TLS1.3 Disabled 하니까 됨
근데 pyppeteer (headless=False) 로 실행하면 Disabled 안되어 있음..ㅋㅋ
headless=True 로 하면 그냥 또 된다..

[Solved] ERR_SSL_VERSION_INTERFERENCE 크롬 오류 수정 - GeekingUp
SSL 인증을 받은 특정 또는 여러 웹사이트에 액세스할 수 없는 경우가 발생할 수 있습니다. Chrome이 반환하는 오류 코드가 ERR_SSL_VERSION_INTERFERENCE, 다음과 관련된 오류입니다. SSL certificate 웹사이트
geekingup.org
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False,
ignoreHTTPSErrors=True,
args=['--ignore-certificate-errors',
'--window-size=1366,768',
'--disable-notifications',
'--disable-features=tls13-variant',
'--disable-features=tls13',
'--disable-tls13',
'--disable-tls13-variant',
],
)
page = await browser.newPage()
await page.goto('chrome://flags')
await page.type('#search', 'tls')
await page.close()
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
https://soyoung-new-challenge.tistory.com/92
[Python] image url을 사용하여 이미지 다운로드
이번 포스팅은 파이썬에서 이미지 주소를 가지고 이미지 파일로 다운로드하는 방법들에 관한 튜토리얼입니다. 인터넷에 존재하는 이미지 파일을 다운로드 하는 다양한 방식 아래 적혀 있는 소
soyoung-new-challenge.tistory.com
List of Chromium Command Line Switches
https://peter.sh/experiments/chromium-command-line-switches/
List of Chromium Command Line Switches « Peter Beverloo
peter.sh
https://developpaper.com/the-pyppeter-library-of-python-crawler-is-simple-to-use/
The pyppeter Library of Python crawler is simple to use - Develop Paper
pyppeteer Before introducing pyppeteer, let’s talk about puppeter. Puppeter is a node based product produced by Google A tool developed by JS is mainly used to manipulate the API of Chrome browser, manipulate Chrome browser through JavaScript code, and c
developpaper.com
#The puppeter supports dictionary parameter transfer
browser = await launch({'headless':True})
#Pyppeter supports dictionary and keyword parameter transfer
browser = await launch({'headless':True})
browser = await launch(headless=True)
#Pyppeter uses Python style function names
page.querySelector()/page.querySelectorAll()/page.xpath()
#Abbreviation
page.J()/page.JJ()/page.Jx()
Simple use
import asyncio
from pyppeteer import launch
async def main():
url = 'https://www.toutiao.com/'
#If the headless parameter is set to false, the headless mode will be changed
browser = await launch(headless=False, ignoreDefaultArgs=['--enable-automation'])
page = await browser.newPage()
#Set page view size
await page.setViewport(viewport={'width':1600,'herght':900})
#Whether to enable JS. If enabled is set to false, there will be no rendering effect
await page.setJavaScriptEnable(enabled=True)
#Waiting time 1000 ms
res = await page.goto(url,options={'timeout':1000})
resp_ Headers = res.headers # response header
resp_ Status = res.status # response status
#Wait
await asyncio.sleep(2)
await page.waitFor(1000)
#The second method is to forcibly query an element in the while loop and wait
while not await page.querySelector('.t')
#Scroll to the bottom of the page
await page.evaluate('window.scrollBy(0,document.body.scrollHeight)')
await page.screenshot({'path':'test.png'})
#Print web cookies
print(await page.cookies())
#Get all HTML content
print(await page.content())
dimensions = await page.evaluate(pageFunction='''() => {
return {
width:document. documentElement. Clentwidth, // page width
height:document. documentElement. Clentheight, // page height
deviceScaleFactor: window. Devicepixelratio, // pixel ratio 1.0000000149011612
}
}''',force_ expr=False) # force_ Expr = false executes a function
print(dimensions)
content = await page. Evaluate (pagefunction ='Document. Body. Textcontent ', force_expr = true) # only get text, execute JS script, force_ Expr = true executes an expression
print(content)
#Prints the title of the current page
print(await page.title())
#You can use XPath expressions to grab news content
'''
Three parsing methods of pyppeter
page.querySelector()
page.querySelectorAll()
page.xpath()
The abbreviation is:
page.J()
page.JJ()
page.Jx()
'''
element = await page.querySelector(".feed-infinite-wrapper > ul>li")
print(element)
element = await page.querySelectorAll(".title-box a")
for item in element:
print(await item.getProperty('textContent'))
#Get text content
title_str = await (await item.getProperty('textContent')).jsonValue()
title_link = await (await item.getProperty('textContent')).jsonValue()
#Get property value
# title = await (await item.getProperty('class')).jsonValue()
print(title_str,title_link)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
Simulate text input and click
#Analog input account password parameter {'delay': reach_int()} delay input time
await page. Type ('#kw', 'Baidu', delay = 100)
await page.type('#TPL_username_1',"asdasd")
await page.waitFor(1000)
await page.click('#su')
Removing chrome is under the control of automated testing software
browser = await launch(headless=False, ignoreDefaultArgs=['--enable-automation'])
#Add ignoredefaultargs = ['-- enable automation'] parameter
Climb Jingdong Mall
from bs4 import BeautifulSoup
from pyppeteer import launch
import asyncio
def screen_size():
return 1600,900
async def main(url):
browser = await launch({"args":['--no-sandbox'],}) # "headless":False
page = await browser.newPage()
width, height = screen_size()
await page.setViewport(viewport={'width':width,'height':height})
await page.setJavaScriptEnabled(enabled=True)
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36')
await page.goto(url)
await page.evaluate('window.scrollBy(0, document.body.scrollHeight)')
await asyncio.sleep(1)
# content = await page.content()
li_list = await page.xpath('//*[@id="J_goodsList"]/ul/li')
item_list = []
for li in li_list:
a = await li.xpath('.//div[@class="p-img"]/a')
detail_url = await (await a[0].getProperty('href')).jsonValue()
promo_words = await (await a[0].getProperty('title')).jsonValue()
a_ = await li.xpath('.//div[@class="p-commit"]/strong/a')
p_commit = await (await a_[0].getProperty('textContent')).jsonValue()
i = await li.xpath('./div/div[3]/strong/i')
price = await (await i[0].getProperty('textContent')).jsonValue()
em = await li.xpath('./div/div[4]/a/em')
title = await (await em[0].getProperty('textContent')).jsonValue()
item = {
"title" : title,
"detail_url" : detail_url,
"promp_words" : promo_words,
"p_commit" : p_commit,
"price" : price
}
item_list.append(item)
await page_close(browser)
return item_list
async def page_close(browser):
for _page in await browser.pages():
await _page.close()
await browser.close()
url = 'https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&wq='\
'%E6%89%8B%E6%9C%BA&pvid=e07184578b8442c58ddd65b221020e99&page={}&s=56&click=0 '
task_list = []
for i in range(1,4):
page = i * 2 - 1
task_list.append(main(url.format(page)))
results = asyncio.get_event_loop().run_until_complete(asyncio.gather(*task_list))
for i in results:
print(i,len(i))
print('*'*100)
https://intrepidgeeks.com/tutorial/basic-use
pyppeter(python 판 puppeter)기본 사용
Django_Relation(Like) Like 구현하기 여러 유저가 한 Article에 좋아요를 누를 수 있고, 한 유저가 여러 Article에 좋아요를 누를 수 잇다. model 구성 error 발생 원인 user와 접근과 like_user의 접근이 겹쳤기 때
intrepidgeeks.com
import asyncio
from pyppeteer import launch
import time
async def main():exepath = 'C:/Users/tester02/AppData/Local/Google/Chrome/Application/chrome.exe'
browser = await launch({'executablePath': exepath, 'headless': False, 'slowMo': 30})
page = await browser.newPage()
await page.setViewport({'width': 1366, 'height': 768})
await page.goto('http://192.168.2.66')
await page.type("#Login_Name_Input", "test02")
await page.type("#Login_Password_Input", "12345678", )
await page.waitFor(1000)
await page.click("#Login_Login_Btn")
await page.waitFor(3000)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
import asyncio
import time
from pyppeteer import launch
async def gmailLogin(username, password, url):
#'headless': False False True
# 127.0.0.1:1080 ip , , vps '--proxy-server=127.0.0.1:1080'
browser = await launch({'headless': False, 'args': ['--no-sandbox', '--proxy-server=127.0.0.1:1080']})
page = await browser.newPage()
await page.setUserAgent(
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36')
await page.goto(url)
# Gmail
await page.type('#identifierId', username)
#
await page.click('#identifierNext > content')
page.mouse #
time.sleep(10)
# password
await page.type('#password input', password)
#
await page.click('#passwordNext > content > span')
page.mouse #
time.sleep(10)
# DONE
# await page.click('div > content > span')# , page.setUserAgent user-agent ,
# , , python 。
#
await page.screenshot({'path': './gmail-login.png', 'quality': 100, 'fullPage': True})
# , Youtube
await page.goto('https://www.youtube.com')
time.sleep(10)
if __name__ == '__main__':
username = ' gmail @gmail.com'
password = r' gmail '
url = 'https://gmail.com'
loop = asyncio.get_event_loop()
loop.run_until_complete(gmailLogin(username, password, url))
# , www.sanfenzui.com, :
# https://blog.csdn.net/Chen_chong__/article/details/82950968
'Python > 스크롤링' 카테고리의 다른 글
| [Python] 크롤링 Bookmarks (0) | 2022.07.24 |
|---|---|
| [Python] Selenium (0) | 2022.05.04 |