Azure 체험 계정 가입함 : 12개월 인기무료 + 30일 크레딧 \224,930

12개월 무료 제품

항상 무료? 제품

Azure Machine Learning 서비스 설명서
https://docs.microsoft.com/ko-kr/azure/machine-learning/service/

Azure Machine Learning 서비스 설명서 - 자습서, API 참조
Azure Machine Learning Service는 신속하게 데이터를 준비하고, 기계 학습 모델을 학습 및 배포할 수 있는 SDK 및 서비스를 제공합니다. 자동 크기 조정 컴퓨팅 및 파이프라인을 사용하여 생산성을 개선하고 비용을 줄이세요. PyTorch, TensorFlow 및 scikit-learn과 같은 오픈 소스 Python 프레임워크와 함께 이러한 기능을 사용하세요. 빠른 시작 및 자습서를 시작해 보세요.
docs.microsoft.com
Azure Machine Learning Service
- 신속하게 데이터 준비, 기계 학습 모델을 학습 및 배포할 수 있는 SDK 및 서비스를 제공
- 자동 크기 조정 컴퓨팅 및 파이프라인을 사용하여 생산성을 개선
- PyTorch, TensorFlow 및 scikit-learn과 같은 오픈 소스 Python 프레임워크와 함께 이러한 기능 사용 가능
Microsoft Azure에 로그인
로그인 Microsoft Azure(으)로 계속 계정이 없으십니까? 새로 만드세요! 본인 계정으로 로그인할 수 없습니까? ©2019 Microsoft 사용 약관 개인정보처리방침
portal.azure.com
* Azure Portal에 로그인 후 [+ 리소스 만들기] -> Machine Learning service workspace (Machine Learning 서비스 작업 영역) -> 만들기



|
필드 |
설명 |
|
작업 영역 이름 |
작업 영역을 식별하는 고유한 이름을 입력합니다. 이 예제에서는 docs-ws를 사용합니다. 이름은 리소스 그룹 전체에서 고유해야 합니다. 다른 사용자가 만든 작업 영역과 구별되고 기억하기 쉬운 이름을 사용하세요. |
|
구독 |
사용할 Azure 구독을 선택합니다. |
|
리소스 그룹 |
구독에서 기존 리소스 그룹을 사용하거나 이름을 입력하여 새 리소스 그룹을 만듭니다. 리소스 그룹은 Azure 솔루션에 관련된 리소스를 보유하는 컨테이너입니다. 이 예에서는 docs-aml을 사용합니다. |
|
Location |
사용자 및 데이터 리소스와 가장 가까운 위치를 선택합니다. 작업 영역이 만들어지는 위치입니다. |
* 만들기 - 작업 영역 만드는 데 몇 분 정도 소요됨
* 배포상태 확인 : 도구 모음에서 알림 아이콘(종모양)을 선택

Azure Notebook에서 시작 - 눌러서 노트북 실행하고 튜토리얼을 실습. Python 3.6 사용.
https://docs.microsoft.com/ko-kr/azure/machine-learning/service/tutorial-data-prep

회귀 모델 자습서: 데이터 준비 - Azure Machine Learning service
이 자습서의 1부에서는 Azure Machine Learning SDK를 사용하여 회귀 모델링을 위해 Python으로 데이터를 준비하는 방법을 배웁니다.
docs.microsoft.com
택시 운행 비용 예측 - 날짜 및 시간, 승객 수 위치 선택이 포함됨
A. Regression modeling을 위한 데이터 준비
1. 데이터 로드
- auto_read_file() method는 입력 파일 형식을 자동으로 인식함
- Dataflow 개체는 데이터 프레임하고 비슷하고,
represents a series of lazily-evaluated, immutable operations on data.
Operations can be added by invoking the different transformation and filtering methods available.
The result of adding an operation to a Dataflow is always a new Dataflow object.
2. 데이터 정리(형식 및 필터 변환, 열 분할 및 이름 바꾸기)
- 전체 Null 데이터 제거(기계 학습 모델의 정확도를 높이는 데 도움이 됨)
- 유효한 열 정하고 열 이름 변경
- 형식 변경 : 위경도 10진 형식으로 변경, distance 숫자 형식으로 변환
- 뉴욕시가 아닌 좌표 & 누락된 좌표 (도시 밖) 필터링 함 (주관적 분석) : 최소, 최대 경계 정의로 필터링함.
- store_forward 값 누락된 부분은 "N"으로 바꾼다.
- 날짜/시간 값을 각각 날짜 및 시간 열로 분할
3. 데이터 변환 ( 원래 날짜 형식 : 2013-08-01 08:14:37 )
- 승차&하차 날짜를 요일, 월간 일자, 월 값으로 추가 분할함. 원래 날짜는 삭제 (pickup_datetime, dropoff_datetime)
(시간, 분 및 초 같은 세밀한 시간 기능은 모델 학습에 유용)
(새로운 시간 기반 기능을 만들면 기계 학습 모델 정확도가 향상됨. 예를 들어 평일에 대한 새 기능을 생성하면 평일과 택시 요금 간의 관계를 설정하는 데 도움이 되며, 특정 요일에는 수요가 많아 요금이 더 비싼 경우가 자주 있다.)
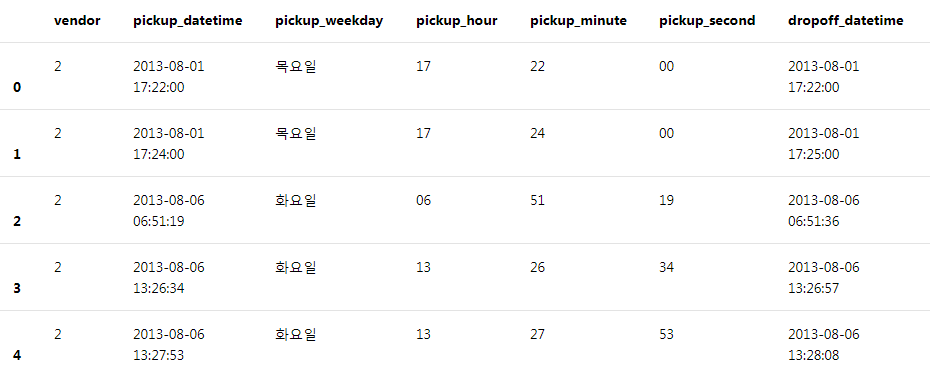
- 최종 필터 : distance > 0, cost > 0
★ 이 단계를 수행하면 기계 학습 모델 정확도가 대폭 향상됨
★ 비용 또는 거리가 0인 데이터 요소는 예측 정확도를 떨어트리는 중대한 이상값을 나타내기 때문
- 머신러닝 모델에 사용할 수 있도록 완전히 변환 & 준비된 dataflow 개체가 생겼다 : dflows.dprep으로 저장
import os file_path = os.path.join(os.getcwd(), "dflows.dprep") final_df.save(file_path)
B. ML 모델 자동 학습
1. 데이터 탐색 (학습 및 테스트 세트로 데이터 분할; Split the data into train and test sets)
- 이전에 만든 dataflow 개체 dflows.dprep 파일을 열어서 결과를 검토함
import azureml.dataprep as dprep file_path = os.path.join(os.getcwd(), "dflows.dprep") dflow_prepared = dprep.Dataflow.open(file_path) dflow_prepared.get_profile()
- dflow_x : 실험용 데이터
- dflow_y : 예측값 - 비용
dflow_X = dflow_prepared.keep_columns(['pickup_weekday','pickup_hour', 'distance','passengers', 'vendor']) dflow_y = dflow_prepared.keep_columns('cost')
- sklearn 라이브러리에서 train_test_split 함수 사용해서 데이터를 학습, 테스트 세트로 분할한다. 이 함수는 데이터를 모델 학습용 x(기능) 데이터 세트 및 테스트용 y(예측 값) 데이터 세트로 분리한다. test_size 매개변수는 테스트에 할당할 데이터 백분율을 정의. random_state 매개변수는 학습-테스트 분할이 항상 결정적이 되도록 임의 생성기에 시드를 설정한다.
from sklearn.model_selection import train_test_split x_df = dflow_X.to_pandas_dataframe() y_df = dflow_y.to_pandas_dataframe() x_train, x_test, y_train, y_test = train_test_split(x_df, y_df, test_size=0.2, random_state=223) # flatten y_train to 1d array y_train.values.flatten()
- 이 단계의 목적 : 데이터 요소에서 실제 정확도를 측정하기 위해 모델 학습에 사용되지 않은 완료된 모델을 테스트하는 것이다.
- 즉, 잘 학습된 모델은 아직 확인되지 않은 데이터에서 정확한 예측을 수행할 수 있어야 한다.
- 이제 모델을 위한 자동 학습에 필요한 패키지 및 데이터가 준비되었다.
The purpose of this step is to have data points to test the finished model that haven't been used to train the model, in order to measure true accuracy. In other words, a well-trained model should be able to accurately make predictions from data it hasn't already seen. You now have the necessary packages and data ready for autotraining your model.
2. 자동으로 모델 학습 (Automatically train a model)
1. Define settings for the experiment run. Attach your training data to the configuration, and modify settings that control the training process.
(experiment 실행을 위한 설정을 정의하고 training 데이터를 configuration에 연결, training process를 제어하는 settings를 수정한다. )
2. Submit the experiment for model tuning. After submitting the experiment, the process iterates through different machine learning algorithms and hyperparameter settings, adhering to your defined constraints. It chooses the best-fit model by optimizing an accuracy metric.
(모델 튜닝을 위한 실험을 제출 한 후, process는 니가 정의한 constraints를 준수하는 different 기계학습 알고리즘 & hyperparameter settings을 반복한다. 정확도 메트릭을 최적화하여 가장 적합한 모델을 선택한다.)
자동 생성 및 튜닝을 위한 설정 정의 (Define settings for autogeneration and tuning)
Define the experiment parameter and model settings for autogeneration and tuning.
자동생성과 튜닝을 위한 실험 매개변수하고 모델에 대한 설정을 정의한다.
View the full list of settings.
Submitting the experiment with these default settings will take approximately 10-15 min,
기본 설정을 사용해서 실험을 제출하는데, 약 10~15분
but if you want a shorter run time, reduce either iterations or iteration_timeout_minutes.
iterations / iteration_timeout_minutes 중 하나를 줄이면 실행 시간을 줄일 수 있다.
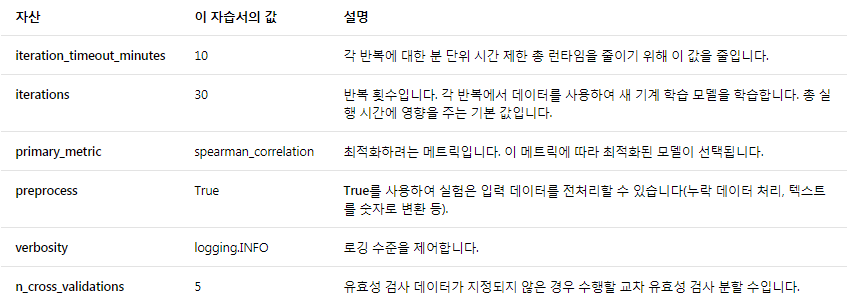
automl_settings = { "iteration_timeout_minutes" : 10, "iterations" : 30, "primary_metric" : 'spearman_correlation', "preprocess" : True, "verbosity" : logging.INFO, "n_cross_validations": 5 }
AutoMLConfig에 대한 매개변수로 정의된 학습 설정을 사용한다. (automl_settings)
또한 학습 데이터 및 모델의 유형을 지정합니다. (우리는 regression)
from azureml.train.automl import AutoMLConfig # local compute automated_ml_config = AutoMLConfig(task = 'regression', debug_log = 'automated_ml_errors.log', path = project_folder, X = x_train.values, y = y_train.values.flatten(), **automl_settings)
자동 회귀 모델 학습
실험을 시작하여 로컬로 실행합니다. 정의된 automated_ml_config 개체를 실험에 전달합니다. 실험하는 동안 진행률을 확인하려면 출력을 True로 설정합니다.
from azureml.core.experiment import Experiment experiment=Experiment(ws, experiment_name) local_run = experiment.submit(automated_ml_config, show_output=True)
표시되는 출력은 실험이 실행됨에 따라 실시간으로 업데이트된다.
각 반복의 경우 모델 유형, 실행 지속 및 학습 정확도가 표시됨
PIPELINE, DURATION, METRIC, BEST
필드 BEST는 메트릭 유형에 따라 최적의 실행 학습 점수를 추적한다.
3. 결과 탐색
Jupyter 위젯을 사용하거나 실험 기록을 검사하여 자동 학습 결과를 살펴봅니다.
옵션 1: 결과를 보여 주는 Jupyter 위젯 추가
Jupyter Notebook을 사용하는 경우 이 Jupyter Notebook 위젯을 사용하여 모든 결과에 대한 그래프 및 테이블을 확인
from azureml.widgets import RunDetails RunDetails(local_run).show()
옵션 2: Python에서 모든 실행 반복 가져오기 및 검사 (Option 2: Get and examine all run iterations in Python)
또는 각 실험의 기록을 검색하고 각 반복 실행에 대한 개별 메트릭을 살펴볼 수 있습니다. 각 개별 모델 실행에 대해 RMSE(root_mean_squared_error)를 검사하여 대부분의 반복이 적절한 여백($3~4) 내에서 택시 요금을 예측하는 것을 알 수 있습니다.
children = list(local_run.get_children()) metricslist = {} for run in children: properties = run.get_properties() metrics = {k: v for k, v in run.get_metrics().items() if isinstance(v, float)} metricslist[int(properties['iteration'])] = metrics rundata = pd.DataFrame(metricslist).sort_index(1) rundata
4. 최적 모델 검색
반복 중에서 최적의 파이프라인을 선택한다.
automl_classifier에 대한 get_output 메서드는 마지막 맞춤 호출에 대한 최적의 실행 및 맞춤 모델을 반환한다.
get_output에 대한 오버로드를 사용하여 모든 기록된 메트릭 또는 특정 반복에 대한 최적의 실행 및 맞춤 모델 검색 가능
best_run, fitted_model = local_run.get_output() print(best_run) print(fitted_model)
5. 최적 모델 정확도 테스트
최적 모델을 사용하여 테스트 데이터 세트에서 예측을 실행하여 택시 요금을 예측한다.
predict 함수는 최적 모델을 사용하고 x_test 데이터 세트에서 y(trip 비용) 값을 예측한다.
y_predict에서 첫 10개의 예측 비용 값을 출력
y_predict = fitted_model.predict(x_test.values) print(y_predict[:10])
실제 비용 값과 비교하여 예측 비용 값을 시각화하는 산점도(a scatter)를 만든다.
다음 코드에서는 distance 기능(feature)을 x-축으로, trip cost를 y-축으로 사용한다.
각 trip 거리 값에서 예측 비용의 차이를 비교하기 위해 처음 100개의 예측 및 실제 비용 값이 separate series로 만들어집니다.
도표를 살펴보면 거리/비용 관계가 거의 선형이고, 대부분의 경우 예측 비용 값이 동일한 여행 거리에 대한 실제 비용 값에 매우 가깝다는 것을 알 수 있다.
import matplotlib.pyplot as plt fig = plt.figure(figsize=(14, 10)) ax1 = fig.add_subplot(111) distance_vals = [x[4] for x in x_test.values] y_actual = y_test.values.flatten().tolist() ax1.scatter(distance_vals[:100], y_predict[:100], s=18, c='b', marker="s", label='Predicted') ax1.scatter(distance_vals[:100], y_actual[:100], s=18, c='r', marker="o", label='Actual') ax1.set_xlabel('distance (mi)') ax1.set_title('Predicted and Actual Cost/Distance') ax1.set_ylabel('Cost ($)') plt.legend(loc='upper left', prop={'size': 12}) plt.rcParams.update({'font.size': 14}) plt.show()
결과의 root mean squared error를 계산한다.
y_test 데이터 프레임을 사용하고 이를 목록으로 변환하여 예측 값과 비교한다.
mean_squared_error 함수는 두 개의 값 배열을 사용하고 두 배열 간의 평균 제곱 오차를 계산한다.
결과의 제곱근을 구하면 y 변수(비용)와 동일한 단위에서 오류가 나타난다.
이는 대략적으로 실제 요금과 택시 요금 예측 간 차이를 나타낸다. $3.2??
from sklearn.metrics import mean_squared_error from math import sqrt rmse = sqrt(mean_squared_error(y_actual, y_predict)) rmse
3.2204936862688798
전체 y_actual 및 y_predict 데이터 세트를 사용하여 MAPE(절대 평균 백분율 오차)를 계산하려면 다음 코드를 실행한다.
이 메트릭은 각 예측 및 실제 값 사이 절대값 차이를 계산하며 모든 차이를 합산한다.
그런 다음, 실제 값의 합계에 대한 백분율로 해당 합산을 표현한다.
sum_actuals = sum_errors = 0 for actual_val, predict_val in zip(y_actual, y_predict): abs_error = actual_val - predict_val if abs_error < 0: abs_error = abs_error * -1 sum_errors = sum_errors + abs_error sum_actuals = sum_actuals + actual_val mean_abs_percent_error = sum_errors / sum_actuals print("Model MAPE:") print(mean_abs_percent_error) print() print("Model Accuracy:") print(1 - mean_abs_percent_error)
Model MAPE: 0.10545153869569586 Model Accuracy: 0.8945484613043041
최종 예측 정확도 메트릭에서 모델은 데이터 세트의 기능에서 택시 요금을 예측하는 데 적합하다는 것을 알 수 있다. (일반적으로 +- $3.00 내).
기존의 Machine Learning 모델 개발 프로세스는 리소스가 상당히 많이 필요하며, 수십 가지 모델을 실행하고 결과를 비교하는 데 많은 도메인 지식과 시간이 필요한데, 자동화된 기계 학습을 사용하는 것은 시나리오에 대한 다른 여러 모델을 신속하게 테스트하는 좋은 방법이다.
'Machine Learning > Azure ML' 카테고리의 다른 글
| 데이터 로드 (0) | 2019.07.22 |
|---|---|
| Azure ML 순서 (0) | 2019.06.25 |
| AKS 클러스터 만들기 (1) | 2019.06.25 |

